

Mit dem Kernel von C nach Rust – ein Projektbericht zu Effizienz und Sicherheit
Systemnahe Programmierung erfordert eine effiziente und sichere Sprache. Der Erfahrungsbericht beschreibt den Wechsel eines Kernelprojekts von C nach Rust.

(Bild: Matt Antonino/Shutterstock.com)
- Dr. Stefan Lankes
Rust ist den vergangenen Jahren immer populärer geworden, und viele Projekte wechseln zu der noch jungen, als sehr sicher geltenden Programmiersprache, sogar der Linux-Kernel verwendet es in Teilen. Der Android-Hersteller Google hat analysiert, dass die Hauptursache für Android-Schwachstellen die fehlerhafte Verwendung von Speicher ist. Zwar existieren andere Programmiersprachen, die gegenüber C die Sicherheit erhöhen, aber im Bereich der systemnahen Programmierung scheint Rust am verbreitetsten zu sein.

Das hat einen Grund: Rust bietet ein sicheres, effizientes Speichermodell an, das aber auf Garbage Collection, wie es vbeispielsweise von Java eingesetzt wird, verzichtet. Garbage Collection verursacht Overhead zur Laufzeit, da es nicht länger benötigte Speicherbereiche im Betrieb identifiziert und freigibt. Ziel einer Systemsoftware ist jedoch hohe Effizienz, die zusätzlichen Overhead vermeiden will. Rusts Weg ist in diesem Punkt geeigneter, denn es bestimmt zur Kompilierzeit, welche Bereiche wann freizugeben sind. Hierzu führt Rust die Konzepte Ownership (Besitz) und Borrowing (Ausleihen) ein, mit denen immer nur ein Besitzer das Recht hat, ein Objekt freizugeben. Aber durch das Erstellen von Referenzen lässt sich das Objekt verleihen. Dieses Konzept setzt voraus, dass dem Compiler der gesamte Quellcode zur Analyse vorliegt. Ansonsten kann er nicht garantieren, dass es nicht weitere Referenzen gibt und folglich mehrere Besitzer existieren.
Immer wieder finden sich Beispiele, wo Rust Sicherheitslücken vermieden hätte. Beim Aufdecken eines Heap-Overflows im Programm curl stellte dessen Autor Daniel Stenberg zum Beispiel fest, fest, dass das Problem mit Rust nicht aufgetreten wäre, aber eine Umstellung von C nach Rust eine Mammutaufgabe bedeuten würde. Damit hat er völlig recht. Deswegen möchte ich von unseren Erfahrungen beim Wechsel von C nach Rust in unserem systemnahen Kernel-Projekt berichten und hoffe, dass andere damit besser evaluieren können, ob ein Umstieg für ihr Projekt sinnvoll ist.
Der Vorläufer: HermitCore
Ausgegangen sind wir vom Betriebssystem HermitCore, das wir im Jahr 2015 in C geschrieben hatten. HermitCore war eine Mischung aus einem Multikernel und einem Unikernel. Bei einem Multikernel läuft auf jedem Prozessorkern ein eigener Betriebssystemkern. So würden bei einem Achtkern-Prozessor acht unabhängige Betriebssystemkerne laufen, die sich nicht gegenseitig stören. Solche Konzepte wurden u.a. im Bereich des Hochleistungsrechnens verwendet, um Seiteneffekte zu vermeiden und so die Leistung zu erhöhen.
Ein Unikernel stellt ein Library Operating System dar, das den Kernel fest an eine Anwendung bindet und direkt auf der Hardware bootet. Solche Systeme können nur ein Programm mit seinen Threads verwalten, Multi-Processing ist nicht möglich. Library Operating Systems werden häufig in virtualisierten Umgebungen eingesetzt, in denen nur eine Anwendung in einer virtuellen Maschine (VM) läuft. Dies schont Ressourcen und mehrere VMs können gleichzeitig arbeiten. Ein typischer Vertreter dieser Gattung ist Unikraft. HermitCore fand im Bereich des technisch-wissenschaftlichen Rechnens seinen Einsatz.
Geschrieben haben wir HermitCore in Assembler und C, der dominierenden Sprache für systemnahe Programmierung. Dennis Ritchie, Ken Thompson und Brian W. Kernighan hatten sie schließlich genau dafür erfunden. Die Nachteile waren uns bekannt, aber getreu dem Konzept "Never change a running system" rüttelten wir anfangs nicht daran.
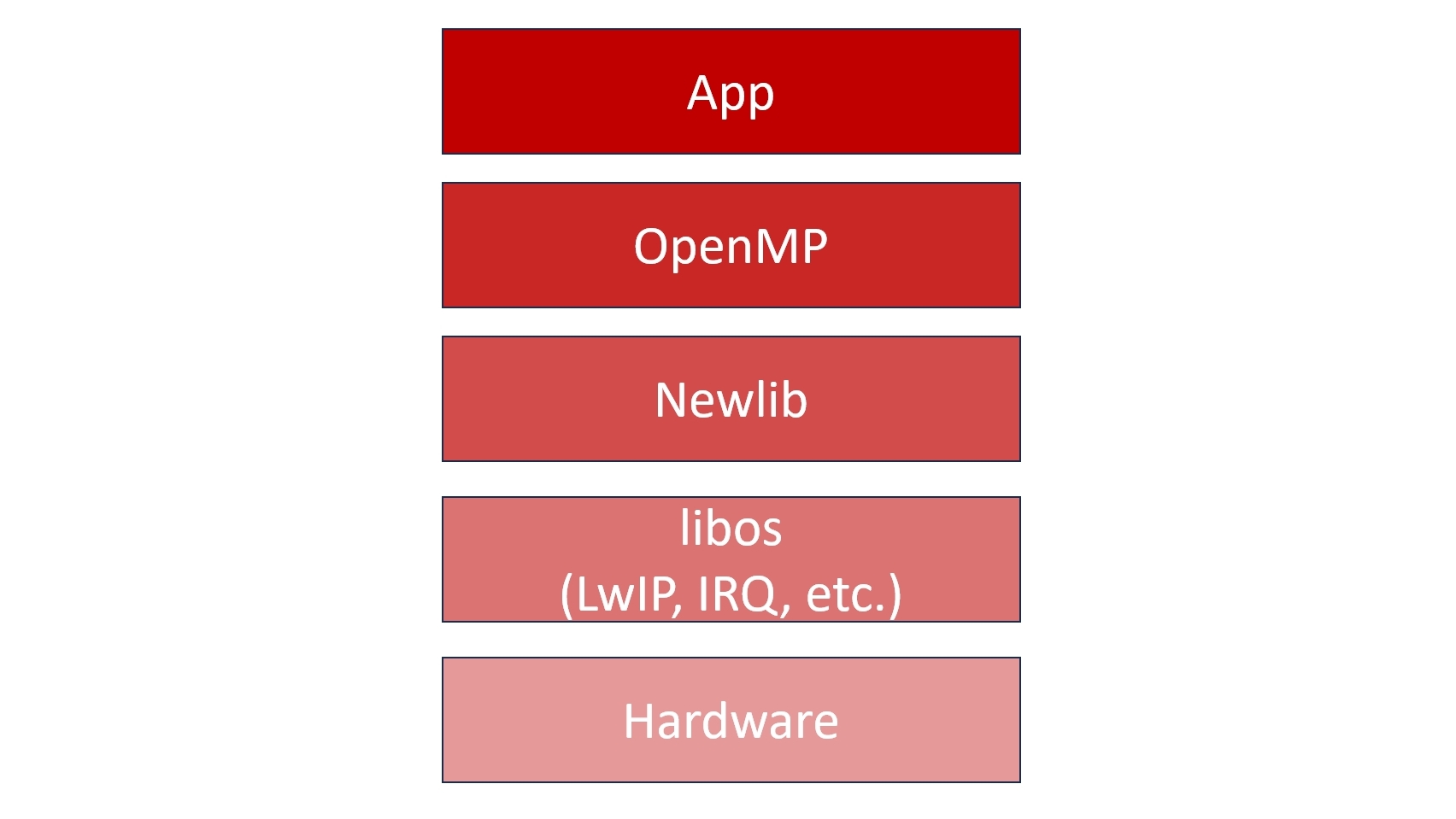
(Bild: Stefan Lankes)
Zum Kernel lieferten wir Systembibliotheken mit, um Anwenderinnen und Anwendern später einen leichten Einstieg zu ermöglichen. Wie die Abbildung 1 verdeutlicht, benötigen Programmierer zum Entwickeln eines einfachen Web-Servers schon eine C Library, eine pthread-Library, einen IP-Stack und einen Cross-Compiler. OpenMP und C++-Support wären auch wünschenswert. Da wir als Kernelentwickler nicht die Anwendungsschicht neu erfinden wollten, griffen wir auf existierende Projekte zurück: zum Beispiel Newlib als C Library, LwIP als IP Stack und die GNU Compiler.
Das alles sind etablierte, aber auch alte Projekte, die teilweise unterschiedliche Build-Systeme (make, automake, cmake, …), Konfigurationsarten und Programmiersprachen verwendeten. Die Maintainer pflegten die verschiedenen Tools mehr oder weniger per Hand. Gab es zum Beispiel eine neue Version, aktualisierten die Betreiber die Git-Repositories, und wir testeten sie mit dem Kernel. Aus heutiger Sicht wäre eine Automatisierung dieser Schritte möglich, aber angesichts der Größe und des Alters der Projekte wäre das keine triviale Aufgabe.
Warum Rust?
Die Motivation von C zu Rust zu wechseln, entstand eher aus Frust über das Build-System als aus dem Wunsch, eine sichere Programmiersprache zu verwenden. Dies klingt naiv, aber Programmiererinnen und Programmierer reden sich gerne ein, dass ihr Code korrekt ist, und sie sind eher über das Drumherum frustriert. Nach kurzer Evaluierung fiel 2017 die Wahl auf Rust. Ein Grund dafür war die saubere Trennung zwischen betriebssystemabhängigen und -unabhängigen Teilen. Der grüne Block in Abbildung 2 zeigt die Core-Bibliothek von Rust. Sie enthält den betriebssystemunabhängigen Teil und kann keinen Speicher anfordern, da das typischerweise die Unterstützung des Betriebssystems braucht.
Das heißt, dass wir alle dynamischen Datenstrukturen nicht in der Core-Bibliothek realisieren konnten, sondern in die Alloc-Bibliothek auslagerten (gelb), die eine Speicherverwaltung voraussetzt. Beide gehören zu den Standard-Bibliotheken (libstd, blau) und werden für diese mit Thread-, Prozesserzeugung, Primitive zur Interprozesskommunikation und Synchronisation ergänzt. Typischerweise schreiben Entwickler die betriebssystemabhängigen Teile mithilfe der externen C-Library des verwendeten Betriebssystems, bei Linux also in der Regel der GNU C Library (rot).

(Bild: Stefan Lankes)
Eine Stärke von Rust ist das Konzept der Crates. Wie die deutsche Übersetzung Kiste oder Schachtel verdeutlicht, wird darin Software beim Ausliefern in logische Einheiten verpackt. Konkret handelt es sich um eine Menge von Dateien, die Rust zusammen kompiliert hat und die sich von anderen Komponenten importieren lassen. Das Erstellen und Verwenden solcher Kisten ist eng mit dem Paketmanager Cargo verwoben.
Er verlangt beim Bauen eines Programmes oder eines Crates eine Spezifikation mit einer Liste von Abhängigkeiten in der Datei Cargo.toml. Meist stehen die Abhängigkeiten ebenfalls als Crate mit Quellcode online zur Verfügung und sind zudem bei Crates.io registriert. Cargo wird den Quellcode aller Abhängigkeiten herunterladen, kompilieren und anschließend zum Programm binden. Das gilt nicht nur für einfache Programme, sondern auch für die Rust-Standard-Bibliothek, die wir nicht nur für den Bau des Kernels benötigten, sondern auch als Ausstattung zu der späteren Anwendung. Über Crates haben wir die Schnittstelle zwischen Rusts Standard-Bibliothek und unserem Unikernel HermitOS ("Rusty Hermit"), dem Nachfolger des HermitCore, integriert (rot in Abbildung 3: hermit-abi).
Der folgende Ausschnitt aus der Spezifikationsdatei der Rust Standard-Bibliothek verdeutlicht, dass beim Target (Zielbetriebssystem für den Compiler) hermit das Crate hermit-abi eingebunden wird, das die Schnittstelle zum Unikernel darstellt. Hierzu registrierten wir unseren Target-Namen beim Rust-Projekt, sodass der Rust-Compiler Objektcode für HermitOS erzeugen konnte. Zudem hinterlegten wir den Quellcode der hermit-abi-Schnittstelle zum Kernel bei Crates.io, sodass beim Erzeugen der Standard-Bibliothek der Quellcode automatisch heruntergeladen und mitgebaut wird. Die Zeile [target.'cfg(target_os = "hermit")'.dependencies] spezifiziert, dass die nachfolgenden Zeilen nur für HermitOS gültig sind.
[package]
name = "std"
version = "0.0.0"
license = "MIT OR Apache-2.0"
repository = "https://github.com/rust-lang/rust.git"
description = "The Rust Standard Library"
edition = "2021"
[target.'cfg(target_os = "hermit")'.dependencies]
hermit-abi = { version = "0.3", features = ['rustc-dep-of-std'] }Wie die Abbildung 3 verdeutlicht, bindet das Crate hermit-abi den Kernel ein. Dieser verwendet wieder die Core- und die Alloc-Bibliothek, da beide Bibliotheken auf derselben Code-Basis aufbauen. Im Unterschied zu der Standard-Bibliothek libstd wird im Kernel auch die Speicherverwaltung realisiert. Dies bedeutet, dass libhermit seine Speicherverwaltung bei der libstd registriert. Durch diese Vorgehensweise ist der Kernel sehr ähnlich zu einem normalen Rust-Programm aufgebaut. Es verwendet die gleichen Datenstrukturen, wie z.B. Vektoren und Warteschlangen.

(Bild: Stefan Lankes)
Wie die Abbildung 3 auch verdeutlicht, kann der Kernel wiederum von anderen Crates abhängen, Beispiele sind smoltcp (IP-Stack) und x86_64 (Interrupt Controllers). Die Wiederverwendung von Code aus anderen Projekten vereinfacht die Kernel-Entwicklung erheblich. Diese Pakete dürfen allerdings nicht wiederum von der Rust Standard-Bibliothek abhängen, da sonst eine gegenseitige Abhängigkeit entstünde.
Zudem besteht die Architektur aus Abbildung 3 nur aus quelloffenem Rust-Code, und der Compiler könnte ihn theoretisch entsprechend komplett analysieren. Allerdings würden über hermit-abi Rusts Standard-Bibliotheken abhängig vom Kernel und dessen Abhängigkeiten (x86_64, smoltcp) werden. Solche Szenarien will die Rust Community vermeiden, um nicht das ganze Projekt von Crates abhängig zu machen, die eventuell von ihren Maintainern nicht mehr gepflegt werden.
Daher sieht das Hermit-Konzept vor, den Kernel und seine Abhängigkeiten als statische Bibliothek anzulegen und später an die Anwendung anzubinden. Die Funktionen für diese Bindung verwenden die C Calling Convention, die definiert, wie C-Funktionen ihre Argumente und Rückgabewerte übergeben. Durch die C Calling Convention kann binär-kompatibilität garantiert werden, und der Kernel kann Rust-fremde Laufzeitumgebungen unterstützen. So ist mit der C Calling Convention doch noch etwas C in unserem Projekt übrig geblieben.
Das sollten Interessenten beim Umstieg beachten
Jetzt stellt sich die Frage, wie aufwendig die Portierung von C nach Rust war. Manche Teile waren zwar leicht zu portieren, einige Konzepte mussten wir jedoch überdenken. Ein Beispiel aus der Linux-Welt: Linux-Treiber bieten eine standardisierte Schnittstelle an: eine Pseudo-Datei im Verzeichnis /dev, auf die Anwendungen zugreifen, um das Gerät zu öffnen, davon zu lesen und es zu beschreiben. Im Gegenzug muss der Treiber Funktionen zur Verfügung stellen, die die entsprechenden Anfragen umsetzen. Das realisieren Treiber-Programmierer üblicherweise über eine Datenstruktur mit Funktionszeigern, die die Funktionen des Treibers beim Kernel anmelden, wie das folgende Beispiel in C verdeutlicht:
struct file_operations {
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
…
};
Zeiger und Funktionszeiger in Rust zu verwenden, ist prinzipiell möglich, allerdings kann der Compiler die Korrektheit nicht überprüfen, sodass Entwicklerinnen und Entwickler solche Teile als unsafe deklarieren müssen. Das sollte so weit wie möglich unterbleiben. In Rust gibt es ein besseres Konzept, das der Traits. Ein Trait bündelt Funktionen und Methoden, die der jeweiligen Datenstruktur zugefügt werden. Das folgende Beispiel stellt vereinfacht Traits für einen Treiber dar.
trait Driver {
fn open(&mut self, path: &String, flags: OpenOptions) -> Result<Box<dyn Handle>>;
}
trait Handle {
fn read(&mut self, buf: &mut [u8]) -> Result<usize>;
fn write(&mut self, buf: &[u8]) -> Result<usize>;
}Der Treiber implementiert eine Datenstruktur, die den Trait Driver umsetzt, der das Öffnen des Geräts ermöglicht und dann eine Datenstruktur, die Lese- und Schreiboperationen zurückgibt. Diese Datenstruktur wiederum müsste die Schnittstellen des Traits Handle erfüllen. Da der Compiler die genaue Umsetzung bei der Definition der Traits und auch dessen Größe nicht kennt, wird beim Rückgabewert der Funktion open das Trait Handle mit dem Präfix dyn erweitert. So weiß der Compiler, dass die Größe des Rückgabewertes erst zur Laufzeit bekannt ist. Box spezifiziert, dass der Rückgabewert auf dem Heap liegen muss.
Beim Transfer von C nach Rust stellt das keine große Hürde dar. Gegenüber der C-Schnittstelle fällt die fehlende Funktion release für das Schließen des Treibers auf. Bei Rust können Programmiererinnen und Programmierer darauf verzichten, da das Freigeben der Datenstruktur das Schließen des Treibers bedeutet. Rust bietet durch den Trait Drop die Möglichkeit eines Destruktors, der die Aufgabe von release übernimmt.
Es gibt aber auch beliebte C-Konzepte, die in Rust nicht so einfach funktionieren oder die Rust-Features benötigen, die kaum verwendet werden oder noch nicht zum stabilen Entwicklungszweig gehören. Zum Beispiel ist es in C üblich, beim Versenden von Daten einen Header anzulegen, der unter anderem die Länge der Nachricht beschreibt. Die gesamte Nachricht legen Entwicklerinnen und Entwickler im virtuellen Speicher ab, um sie effizienter zu versenden. Das folgende Beispiel zeigt ein einfaches C-Gerüst für eine solche Nachricht in variabler Länge. Es verdeutlicht auch, wo die Gefahren in C liegen: Die Funktionen produce_data und create_checksum müssen darauf vertrauen, dass die Größe des Puffers data mit der übergebenen Länge übereinstimmt. Zudem geht das Beispiel recht lax mit den Datentypen um.
struct header {
size_t length;
int checksum;
};
int produce_data(char* data, size_t len);
int create_checksum(char* data, len);
char* create_message(size_t len) {
struct header* message = (struct header*)
malloc(sizeof(struct header)+len);
message->len = len;
produce_data((char*) (message+1), len);
message->checksum = create_checksum((char*) (message+1),
len);
return (char*) message;
}Grundsätzlich ist es in Rust ebenfalls möglich, eine Nachricht mit variabler Länge zu erzeugen. Das nächste Listing erzeugt in Rust die Datenstruktur Message, die eine beliebige Größe hat, da sie einen sogenannten Slice ([u8]) enthält. Slice beschreibt eine kontinuierliche Sequenz von Daten, deren Länge zur Kompilierzeit nicht bekannt sein muss. Soll ein Programm ein solches Element erzeugen, muss es den zugehörigen Speicher explizit anfragen. Dies ist einer der wenigen Fällen, in dem die Speicherverwaltung in Rust direkt aufgerufen wird.
Hierzu erzeugen Programmiererinnen und Programmierer die Datenstruktur Layout, die die Größe und die Ausrichtung (Alignment) der Nachricht beschreibt. alloc fordert den Speicher an und wandelt anschließend in die Datenstruktur Message um. Anschließend beinhaltet die Referenz die Größe der Datenstruktur und somit implizit die Größe des Slice data.
Diese Schritte müssen Entwickler als unsafe kennzeichnen, da Zeiger zum Einsatz kommen. unsafe-Regionen sollten vermieden werden, aber hier wird einmalig eine unsafe-Datenstruktur erzeugt, die anschließend verwendet werden kann, ohne den Zugriff im Folgenden weiter mit unsafe kennzeichnen zu müssen. Funktionen wie produce_data und create_checksum können mit Referenzen arbeiten, die die Größe der referenzierten Daten erst zur Laufzeit kennen.
#[repr(C)]
pub struct Header {
pub length: usize,
pub checksum: u32,
}
#[repr(C)]
pub struct Message {
pub header: Header,
pub data: [u8],
}
pub fn create_message(len: usize) -> Box<Message> {
let layout = Layout::from_size_align(
size_of<Header>+len,
align_of<Header>,
);
let mut message = unsafe {
let data = alloc(layout);
let raw = slice_from_raw_parts_mut(data, len) as *mut Message;
Box::from(raw)
};
message.header.len = len;
produce_data(&mut message.data);
message.header.checksum = create_checksum(&message.data);
message
} Fazit und Ausblick
Rust hat sich in den vergangenen Jahren extrem weiterentwickelt. Das Team hat die Integration des Inline-Assemblers komplett überarbeitet, was gegenüber C eine deutliche Verbesserung darstellt. Auch Werkzeuge wie clippy oder die RustSec Advisory Database sind einen Blick wert, um die Code-Qualität deutlich zu erhöhen. Mit Ferrocene steht inzwischen ein nach ISO 26262 und IEC 61508 zertifizierter Rust-Compiler für sicherheitskritische Anwendungen zur Verfügung.
Durch unsafe-Codeblöcken kann auch in Rust ein undefiniertes Verhalten entstehen. Um das zu vermeiden, hilft der experimentelle Interpreter MIRI, der eine Zwischenrepräsentation des Compilers interpretiert, um undefiniertes Verhalten zu erkennen. Es existieren viele Ideen und Ansätze, die die Code-Qualität künftig weiter steigern. Die Tabelle unten verdeutlicht zentrale Unterschiede zwischen Rust und C. Einige Aspekte enthält die Tabelle nicht, die eher weiche Kriterien sind. Zum Beispiel bin ich persönlich durch Rust deutlich produktiver geworden.
|
Wichtige Unterschiede von C und Rust |
||
| Eigenschaft | C | Rust |
| Direkter Hardware-Zugriff | ja | ja |
| Verwendung von Zeigern möglich | ja | ja (unsafe) |
| Integration von anderen Programmiersprachen | Beispielsweise über das System V Application Binary Interface (ABI) möglich | Beispielsweise über das System V Application Binary Interface (ABI) möglich (unsafe) |
| Garbage Collection | nein | nein |
| Memory Safety | nein | ja |
| Strenge Typüberprüfung | nein | ja |
| Inline Assembler | ja | ja |
| Portierbarkeit | ja (LLVM Backend u.a.) | ja (LLVM Backend) |
| Moderne Sprachelemente (Closures, Generics, etc.) | nein | ja |
(who)
