Multithreading-Benchmark: Haskell schlägt Java und Python Update

(Bild: Menna/Shutterstock)
Warum Haskell? Obwohl Java und Python weitaus beliebter sind, zeigen Benchmarks, dass Haskell beim Multithreading einen deutlichen Vorsprung erzielt.
Im März 2024 rangiert Python im Tiobe Programming Community Index [1]wie viele Monate zuvor auf Platz 1, Java hingegen nimmt den vierten Platz ein. Haskell spielt eher am Rand mit und kommt gerade einmal auf den 30. Platz. Unser Multithreading-Benchmark-Test wird allerdings offenbaren, dass Haskell wenigstens bei der Nebenläufigkeit zu Unrecht vernachlässigt wird.

Die Bedeutung von Multithreading
In der Programmierung wird zwischen parallelen Berechnungen (Parallelism) und gleichzeitigen ausführenden Tasks (Concurrency beziehungsweise Multithreading) unterschieden. Beide Techniken haben unterschiedliche Einsatzgebiete: Parallele Programme erzielen Schnelligkeit durch intensiven Gebrauch von Hardware-Ressourcen, insbesondere mehrerer CPU-Kerne. Ein Programm kommt schneller ans Ziel, indem es die Berechnung in mehrere Teile aufteilt, die es an die einzelnen CPU-Kerne delegiert. Die parallele Programmierung zeichnet sich vor allem durch die Effizienz der Berechnung aus, wodurch beispielsweise Sortieralgorithmen profitieren.
Im Gegenzug dazu handelt es sich bei Multithreading beziehungsweise Concurrency um eine Technik, die auf den Einsatz von mehreren Threads basiert. Konzeptionell betrachtet, laufen die Threads zur selben Zeit ab, das heißt, dass Benutzer deren Auswirkungen überlappend wahrnehmen. Ob sie tatsächlich alle zur selben Zeit ausgeführt werden, ist eine Frage der Implementierung. Ein auf Multithreading basierendes Programm lässt sich auf einem einzelnen CPU-Kern betreiben, indem es die Ausführung verschachtelt, oder auf mehrere Kerne oder physische CPUs verteilt. Multithreading kommt vor allem dort zu tragen, wo eine Interaktion des Programms mit mehreren externen Agenten gewünscht ist, die unabhängig voneinander handeln. Beispielsweise basieren Zugriffe mehrerer externer Clients auf einen Datenbank-Server auf Multithreading. Ein weiterer Vorteil des Multithreadings ist die Modularität solcher Programme. Denn ein Thread, der mit Nutzern interagiert, unterscheidet sich von dem, der mit der Datenbank spricht. Entwicklerinnen und Entwickler müssten ohne Multithreading beispielsweise Client/Server-Anwendungen mit Ereignisschleifen und Rückverweisen schreiben, was deutlich mühseliger ist. Die Implementierungen von Concurrency beziehungsweise Parallelität im Allgemeinen unterscheiden sich von Sprache zu Sprache stark, hinsichtlich der Mechanismen, die zum Einsatz kommen, und der sich daraus ergebenden Komplexität (Abbildung 1).
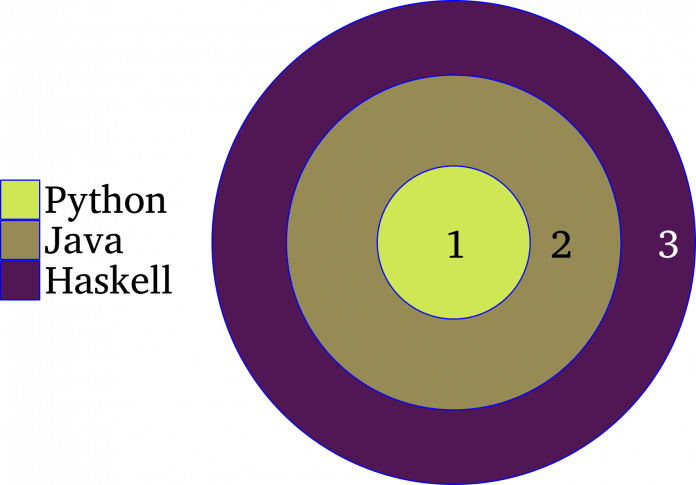
(Bild: Anzela Minosi)
Python und die Sache mit GIL
Der im Januar 2023 unterbreitete Vorschlag PEP 703 [2] an das Python Steering Council, den Global Interpreter Lock (GIL), der das Multithreading erschwert, optional anzubieten [3], ist in der Python-Community auf ein breites Echo gestoßen. Und tatsächlich gibt es mit Version 3.13 zwei Builds: [4] Der Standard wird einige Jahre lang weiterhin mit GIL ausgeliefert, wohingegen der Experimental-Build ohne GIL daherkommt.
GIL sorgt dafür, dass der Python-Interpreter lediglich einen Thread ausführt. Bei Single-Threaded-Programmen wirkt sich das nicht negativ auf die Performance aus, allerdings kann er zu einem Flaschenhals mutieren, sobald CPU-lastige Berechnungen oder Multithreading eine Rolle spielen. Der GIL existiert bei Python lediglich aus einem Grund: Python nutzt zur Speicherverwaltung einen Referenzzähler für alle erstellten Python-Objekte. Dieser zählt die Zeiger, die auf ein Objekt verweisen. Sobald er den Wert Null erreicht, wird der Speicher, den das Objekt belegt, freigegeben. GIL dient als Zugriffssperre, um Race Conditions zu vermeiden, bei denen zwei Threads den Wert des Referenzzählers modifizieren. So verhindert Python Deadlocks. GIL macht de facto aus jedem CPU-lastigen Programm ein Single-Threaded-Programm, was für Single-Threaded-Programme sogar eine Performance-Steigerung bedeutet, da lediglich eine Zugriffssperre erforderlich ist.
Weiter unten wird anhand eines Beispiels dargestellt, wie mit Multiprocessing anstelle von Threads Prozesse zum Einsatz kommen, um die parallele Verarbeitung von Teilen eines Python-Programms trotz GIL umzusetzen. Dabei bekommt jeder Prozess seinen eigenen Python-Interpreter sowie Speicherplatz.
Darüber hinaus existieren weitere Alternativen, um den GIL zu umgehen [5]. Beispielsweise lässt sich der Python-Standardinterpreter CPython ersetzen: Der Fork nogil verzichtet auf GIL. Anschließend kann im eigenen Python-Modul die Threading-Bibliothek importiert werden, um das Programm mit mehreren Threads auszuführen. Diese Methode hat jedoch auch Nachteile, denn nogil basiert auf einer veralteten Python-Version. Zudem lassen sich Bibliotheken von Drittanbietern, die von GIL abhängen, nicht ohne Weiteres installieren oder importieren. Und Code, der mit einem Thread auskommt, arbeitet sogar langsamer.
Eine weiter Methode sind in C geschriebene, über das Foreign Function Interface (FFI) eingebundene Erweiterungsmodule. Das FFI ermöglicht eine Kommunikation mit C-Bibliotheken. Der Code, der auf den Einsatz von mehreren Threads basiert, wird als C-Erweiterungsmodul ausgelagert und mit einem C-Compilers wie gcc kompiliert. Das Resultat ist eine geteilte C-Bibliothek mit der Endung .so. Unter Python lässt sich nun durch den Import der Ctypes-Bibliothek zusammen mit der Threading-Bibliothek der Aufruf einer C-Funktion durch mehrere Threads umsetzen.
Multithreading in Java
Die Programmiersprache Java ist traditionell stärker auf Multithreading ausgerichtet als Python, denn jede Java-Anwendung setzt auf Threads. Sobald die Java Virtual Machine (JVM) startet, erstellt sie Threads, um ihren Pflichten – Garbage Collection, Finalisierung – nachzukommen sowie einen Haupt-Thread, der die Main-Methode ausführt. Darüber hinaus machen Frameworks wie die GUI-Rendering-Bibliotheken JavaFX oder Swing intensiven Gebrauch von Threads, um die Ereignisse an der Benutzerschnittstelle zu verwalten. Daneben gibt es weitere Klassen wie der Timer, um Threads zum Ausführen von verzögerten Aufgaben zu erstellen. Die Thread-Sicherheit unter Java macht es unmöglich, dass ein Objekt in einen illegalen oder inkonsistenten Zustand gerät, unabhängig von den Methodenaufrufen und dem Scheduler des Betriebssystems. Im Vergleich zu Python verfügt Java über eine Vielzahl an Werkzeugen, die eine thread-sichere Implementierung von Multithreading-Anwendungen erlauben. Beispielsweise lassen sich Variablen, auf die mehrere Threads gleichzeitig zugreifen, mit dem Schlüsselwort volatile thread-sicher umsetzen. Bevor eine Funktion auf eine mit volatile markierte Variable zugreift, muss deren Wert aus dem Hauptspeicher neu eingelesen werden. Genauso achtet Java beim Modifizieren dieser Variable darauf, dass nach Beendigung des Schreibprozesses der Wert in den Hauptspeicher zurückgeschrieben wird. Üblicherweise spielen volatile Variablen bei Client/Server-Anwendungen eine Rolle, um damit Run-until-shutdown-Pattern zu implementieren. Auf diese Weise signalisiert ein Client einem laufenden Thread, den aktuell zu bearbeitenden Job zu beenden, damit der Thread ordnungsgemäß heruntergefahren wird.
Blöcke oder Methoden hingegen lassen sich mittels des Schlüsselworts synchronized gegen die Inkonsistenz von Daten absichern. Dadurch wird der Zugriff auf den Code innerhalb eines Blocks oder Methode eingeschränkt. Der kooperative Mechanismus, der sich hinter synchronized verbirgt, setzt sogenannte Monitore als Zugriffssperren ein. Dabei handelt es sich um ein Token, über das jedes Java-Objekt verfügt. Sobald ein Thread Zugriff auf den Block erlangt, beschlagnahmt er den Monitor für sich, führt den Block aus und gibt den Monitor wieder frei. Der nächste Thread, der Zugriff auf den Block erhalten möchte, wird so lange blockiert, bis der Monitor-Holder die Zugriffssperre freigibt.
Das gleichzeitige Ausführen von Code kann unter Java mit der Thread-Klasse implementiert werden, die seit der allerersten Version des Compilers existiert. Gemessen an der Ausführungseinheit, sind Threads im Vergleich zu Prozessen leichtgewichtiger und können dennoch beliebigen Java-Code ausführen. Threads sind Teil jedes beliebigen Prozesses, dessen Adressraum von den Threads gemeinsam genutzt wird. Jeder Thread lässt sich unabhängig voneinander vom Scheduler einplanen und verfügt über einen eigenen Stack und Programmzähler, teilt sich jedoch den Speicher und die Objekte mit anderen Threads desselben Prozesses.
In Summe erlaubt Javas Thread-Model, dass unterschiedliche Threads in einem Prozess Objekte einfach gemeinsam nutzen können, wobei jeder Thread Objekte verändern kann, auf die er verweist. Allerdings ist es für Entwicklerinnen und Entwickler nicht immer einfach, die Zugriffssperren korrekt zu benutzen, und der Zustand gemeinsam geschützter Ressource ist ziemlich gefährdet, auch an unerwarteten Stellen wie ein simpler Lesezugriff. Zudem entscheidet der Scheduler des Betriebssystems darüber, welche Threads gerade laufen.
Haskells Antwort auf Multithreading
Haskell scheint wie geschaffen für Mulithreading zu sein, denn deren Schöpfer haben die üblichen Konzepte neu durchdacht. Haskell ist von Natur aus parallel und verfügt über drei Formen des Multithreading, die sich etwas vereinfacht in zwei Kategorien teilen lassen. Zum einen setzt Haskell Threads ein. Streng genommen stellt ein Thread unter Haskell eine IO-Aktion dar, die unabhängig von den anderen Threads ausgeführt wird. Zum anderen macht Haskell Gebrauch von Parallelität, die anders realisiert wird als ein thread-basiertes Programm.
Die häufigsten Techniken, die zur Umsetzung von Multithreading unter Haskell verwendet werden, sind MVars, Channels sowie Software Transactional Memory (STM). Eine MVar ist im Fachjargon eine thread-sichere Variable, die den Austausch an Informationen zwischen zwei Threads ermöglicht. Sie verhält sich im laufenden Betrieb wie eine Box für lediglich ein Element und kann entweder voll oder leer sein. In sie lässt sich etwas hineinlegen oder herausnehmen. Sobald ein Thread versucht, einen Wert in eine belegte MVar zu legen, wird der Thread in den Schlaf versetzt, bis ein anderer Thread den Wert herausnimmt. Ähnlich verhält sich eine leere MVar: Wird versucht, etwas aus einer leeren MVar zu entnehmen, muss der Thread warten, bis ein anderer Thread darin etwas ablegt.
Haskell setzt verstärkt auf STM, eine Weiterentwicklung von MVar, das eine Abstraktionsebene für Nebenläufigkeit bietet. Operationen lassen sich gruppieren und als singuläre atomare Operation Transaction ausführen. Es ist deutlich weniger problematisch und kennt keine Deadlocks oder Race Conditions. Die Variablen unter STM sind vom Typ TVar, wobei STM ähnlich wie unter Java auf einen ganzen Block angewandt wird. Ein Vorteil, den MVar gegenüber STM hat, ist die Fairness, mit der Threads abgearbeitet werden. Hierzu wendet MVar das First-in-first-out-Prinzip an, was bedeutet, dass Threads der Reihe nach auf die MVar zugreifen.
In Haskell sind die meisten parallelen Programme deterministisch, liefern also reproduzierbare Ergebnisse. Um eine Funktion zu parallelisieren, kommen die Methoden aus dem Modul Control.Parallel zum Einsatz. Dadurch lassen sich gängige Multithreading-Probleme wie Deadlocks und Race Conditions vermeiden.
Testumgebung
Um sich einen aktuellen Überblick über die Umsetzung von Multithreading-basierten Anwendungen zu verschaffen, führten wir Countdown-Tests auf unterschiedlichen Computerarchitekturen durch (siehe Tabellen). Die Compiler stammen aus offiziellen Quellen: Die Python-Interpreter 11 und 12, die beide über den GIL verfügen, installierten wir über die Paketmanager der Distributionen Gentoo und Manjaro, wobei wir zur Ausführung der einzelnen Python-Module, diese lediglich um eine Main-Methode ergänzen.
Zudem installierten wir auf beiden PCs die Java Runtime-Umgebung (JRE) von Liberica [6], wobei unter Gentoo die Version 20.0.2 und bei Manjaro die Version 17.0.9 zum Einsatz kam. Aufgrund der plattformunabhängigen Eigenschaft von Java wurden die auf Java laufenden Programme lediglich auf dem Intel-Computer kompiliert. Für die Java-Tests erstellten wir ein Kommandozeilentool mit Picocli [7], um damit alle drei Testrunden auszuführen. Danach erfolgte die Kompilierung mit dem Maven-Plugins Really-executable-jar, sodass sich das Java-Benchmark-Tool ähnlich wie ein Bash-Skript auf der Konsole ausführen ließ (Abbildung 3).
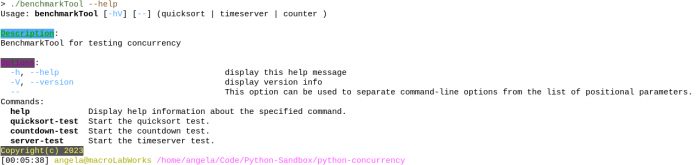
(Bild: Anzela Minosi)
(Bild: Anzela Minosi)
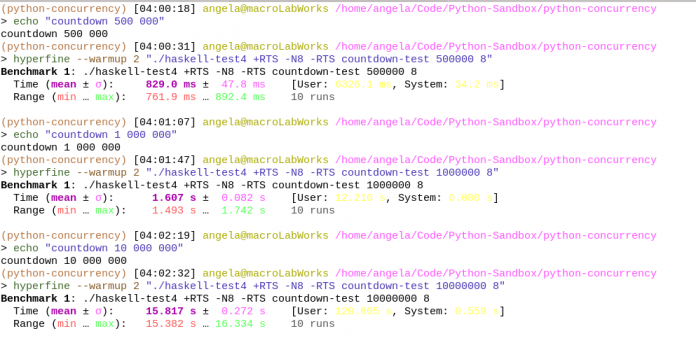
Zur Kompilierung des Haskell-Benchmark-Tools kam auf beiden PCs Stack zum Einsatz [8], wobei dem GHC-Compiler (Version 9.6.3) weitere Argumente übergeben wurden, um Multithreading zu aktivieren. Hierfür verwendeten wir die Option -threaded, um das Haskell-Benchmark-Tool mit der Threaded-Laufzeitbibibliothek zu verknüpfen. Zusätzlich optimierte das Argument -O2 das Haskell-Benchmark-Tool weiter, indem es das Tool verkleinerte. Dadurch dass sich die Python-Programme, das Java-Benchmarktool sowie das Haskell-Benchmarktool auf der Konsole aufrufen ließen, konnten wir alle Benchmarks mit nur einem Tool, Hyperfine [9], durchführen (Abbildung 4). In unserer Umgebung führten wir insgesamt 18 Tests verteilt auf beiden Rechnern aus.
| Spezifikation Testcomputer #1: PC mit ATX-Miditower | |
| CPU | Intel Core i7 870 @ 2.93GHz (8 Kerne / 16 Threads) |
| Mainboard | Asus P7P55D Pro |
| Chipsatz | Intel P55 Express |
| RAM | 16 GByte |
| Festplatte | 500 GByte Seagate ST3500418AS |
| Grafik | GeForce GT 1030 |
| Audio | ASUS XONAR SOUND CARD |
| Netzwerkkarte | Realtek 8112L Gigabit LAN |
| Router | TP-Link TL-MR6500v (10/100 Mbps LAN Ports) |
| Betriebssystem | Gentoo |
| Kernel | 6.4.8-gentoo-x86_64 |
| Desktop-Umgebung | Xfce4 4.18 |
| Display Server | X Server 1.21 |
| Grafikkartentreiber | NVIDIA 535.86.05 |
| Dateisystem | Ext4 |
| Monitorauflösung | 1920x1080 |
| Python-Interpreter | 3.12.1 |
| JRE | Liberica 20.0.2 |
| GHC-Compiler | 9.6.3 |
| Spezifikation Testcomputer #2: Einplatinenrechner | |
| CPU | ARM Cortex-A72 @ 1.5GHz (4 Kerne / 4 Threads) |
| Raspberry Pi | Raspberry Pi 4 Model B |
| RAM | 8 GByte |
| Festplatte | Kingston Canvas Select Mikro-SD-Karte 128 GByte |
| Grafik | VideoCore VI @ 500 MHz (GPU 128 MByte) |
| Audio | Waveshare WM8960 |
| Netzwerkkarte | Gigabit LAN |
| Router | TP-Link TL-MR6500v (10/100 Mbps LAN Ports) |
| Betriebssystem | Manjaro |
| Kernel | 6.1.69-1-MANJARO-RPI4 (AARCH64) |
| Desktop-Umgebung | Mate |
| Display Server | X Server 1.21 |
| Grafikkartentreiber | MESA 25.2 |
| Dateisystem | Ext4 |
| Monitorauflösung | 1920x1080 |
| Python-Interpreter | 3.11.6 |
| JRE | Liberica 17.0.9 |
| GHC-Compiler | 9.6.3 |
Countdown-Test
Vorweg sei gesagt, dass der Performance-Test einer Programmiersprache nicht in völliger Leere stattfinden kann, sondern vom Gesamtsystem, also Bibliotheken, Compilern, Interpretern usw. abhängt. Wir haben versucht, hier eine realistische Umgebung zu schaffen, die einen Vergleich unter quasi lebensechten Bedingungen ermöglicht. Andere Umgebungen können durchaus zu anderen Ergebnissen führen.
Der Countdown-Test bestand darin, von einer großen ganzzahligen Zahl runter auf 0 zu zählen. Um einen repräsentativen Vergleich zu erzielen, nahmen wir pro Compiler jeweils drei Testrunden auf den beiden Testrechnern vor. Dabei wurde die Countdown-Funktion mit den Werten N = 500.000, N = 1.000.000 und N = 10.000.000 getestet. Die Implementation einer auf Multithreading-basierten Countdown-Funktion unterscheidet sich von Programmiersprache zu Programmiersprache.
Unter Python ist es am einfachsten, zunächst eine simple Countdown-Funktion zu erstellen, die solange den Wert einer Variable n um eins reduziert, bis n = 0 ist:
Listing 1: Implementation eines Countdowns unter Python
def countdown(n):
while n>0:
n -= 1
print(n)
Um die Ausführung der Countdown-Funktion zu beschleunigen, kommt die externe Bibliothek Trio-Parallel [10] zum Einsatz:
import trio
async def time_countdown(n):
async with trio.open_nursery() as nursery:
computational_result_aiter = nursery.start_soon(trio_parallel.run_sync, countdown,n)
Unserer Einschätzung zufolge handelt es sich bei Trio-Parallel um die einfachste Art, alle CPU-Kerne während der Ausführung voll auszunutzen. Der Countdown-Test wird schließlich durch den folgenden Code ausgelöst:
import trio
import sys
import multiprocessing
counterN1 = 500000
counterN2 = 1000000
counterN3 = 10000000
if __name__ == '__main__':
multiprocessing.freeze_support()
trio.run(time_countdown,counterN3)Im Vergleich zu Python lässt sich unter Java die Countdown-Funktion unter Zuhilfenahme des Schlüsselworts synchronized thread-sicher implementieren, was dazu führt, dass mehrere Threads gleichzeitig zugreifen können:
public class Countdown {
private long value = 0;
private volatile boolean cancelled = false;
public Countdown(long n) {
this.value = n;
}
public synchronized long getValue() {
return value;
}
public synchronized void decrement() {
if (! isCancelled()) {
while (value > 0) {
this.value--;
System.out.println("Current value:"+this.value);
}
this.cancel();
}
}
public boolean isCancelled() {
return this.cancelled;
}
private void cancel() {
this.cancelled = true;
}
}Um so viele Tasks zu erstellen, wie die CPU über Kerne verfügt, wird ein Task für den Countdown vom Typ Callable implementiert, dem als Argument ein zuvor initialisiertes Objekt vom Typ Countdown übergeben wird. Das stellt sicher, dass alle Threads auf ein und denselben Counter zurückgreifen:
public class CountingTask implements Callable <CountingTask>{
private Countdown countdown;
public CountingTask(Countdown c) {
this.countdown = c;
}
public CountingTask call() {
if (!Thread.currentThread().isInterrupted()) {
this.countdown.decrement();
}
return this;
}
}Zum Verwalten der asynchronen Tasks kommt die Schnittstelle ExecutorService zum Einsatz, die so viele Callables vom Typ Countdown erstellt, wie an Threads numThreads festgelegt worden sind:
public class CountdownService {
// ruft die Zahl der CPU-Kerne ab
public static final int MAX_THREADS = Runtime.getRuntime().availableProcessors();
private ExecutorService executorService;
private Countdown countdown;
private int numThreads = 0;
private Set<Callable<CountingTask>> tasks = Collections.synchronizedSet(new HashSet<Callable<CountingTask>>());
private List<Future<CountingTask>> futures;
public CountdownService(Countdown c, int n) {
this.countdown = c;
this.numThreads = n;
this.executorService = Executors.newFixedThreadPool(MAX_THREADS);
this.futures = new ArrayList<Future<CountingTask>>();
}
// erstellt die Tasks
public void prepare() {
for (int i = 0; i < this.numThreads; i++) {
CountingTask task = new CountingTask(this.countdown);
this.tasks.add(task);
}
}
// initialisiert die Callables
public void init() {
if (!this.executorService.isShutdown()) {
try {
futures = executorService.invokeAll(tasks);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}Danach werden die Tasks gleichzeitig durch Aufruf von executorService.invokeAll(tasks) gestartet:
public void startCountdown(int n, int numThreads) {
Countdown c = new Countdown(n);
CountdownService countdown = new CountdownService(c, numThreads);
countdown.prepare();
countdown.init();
}Haskell verfolgt einen anderen Ansatz, indem die erforderlichen Funktionen in einem Modul implementiert werden:
module MyCounter () where
...
import Control.Monad (forever)
import Control.Concurrent.STM
import Control.Concurrent.MVar
import Control.Concurrent (forkIO,threadDelay)
import System.Exit as Exit
import qualified Lib as Lib
-- komplexe Datentypen
data MyCounter = MyCounter Int deriving (Eq)
data Countdown = C MyCounter | M MAX | N MIN deriving (Show,Eq)
data MAX = MAX Int deriving (Eq)
data MIN = MIN Int deriving (Eq)
type CounterVar = TVar Countdown
-- vergleicht den Zähler mit dem Infimum oder Supremum
myCompare :: Countdown -> Countdown -> Ordering
(M (MAX n)) `myCompare` (C (MyCounter i))
| n == i = EQ
| n < i = LT
| otherwise = GT
(N (MIN n)) `myCompare` (C (MyCounter i))
| n == i = EQ
| n < i = LT
| otherwise = GT
c@(C (MyCounter _)) `myCompare` m@(N (MIN _)) = m `myCompare` c
c@(C (MyCounter _)) `myCompare` m@(M (MAX _)) = m `myCompare` c
-- erstellt einen neuen Countdown mit einem Infimum oder Supremum
resetCounter :: Countdown -> IO CounterVar
resetCounter (M (MAX n)) = do
tstore <- atomically $ newTVar (C (MyCounter n))
return tstore
resetCounter (N (MIN n)) = do
tstore <- atomically $ newTVar (C (MyCounter n))
return tstore
-- reduziert den Countdown um eins
decCounter' :: Countdown -> Countdown
decCounter' (C (MyCounter c)) = C (MyCounter (c - 1))
decCounter :: CounterVar -> Int -> IO ()
decCounter tstore i = do
-- Wert aus der gemeinsam genutzten Variable abrufen
c <- Lib.getTVar tstore
let min' = N (MIN 0)
newCounter = decCounter' c
res = auxCompare min' c
-- prüfen ob der Countdown das Infimum oder Supremum erreicht hat
if (auxCompare min' c == LT )
then do
-- neuen Wert in die TVar ablegen
Lib.modifyTVar_ tstore newCounter
-- rekursiver Aufruf von decCounter
decCounter tstore (Steps (succ n)) i
-- Ansonsnte decCounter verlassen
else (putStrLn $ "Finished Thread Number: " ++ (show i)) >> return ()
where
auxCompare x y = x `myCompare` y
Der Countdown wird zusammen mit einem Infimum MIN oder Supremum MAX durch Aufruf der Funktion resetCounter initialisiert. Auch das ermöglicht eine thread-sichere Implementierung des Countdowns, indem der initiale Wert des Countdowns in die weiter oben erwähnte TVar des STM-Moduls abgelegt wird. Jeder Thread führt dann solange die Funktion decCounter aus, bis der Wert 0 erreicht wird. Dabei wird zunächst der Wert aus der TVar abgerufen und durch Aufruf der Hilfsfunktion myCompare überprüft, ob der Countdown dem Grenzwert entspricht.
Falls das nicht der Fall ist, erfolgt ein rekursiver Aufruf von decCounter, andernfalls bricht der Thread die weitere Ausführung von decCoutner ab. Schließlich startet der Countdown, indem wir der Funktion countdowntest die Zahl der Threads t sowie N als Argumente übergeben:
import Control.Concurrent.Async (replicateConcurrently_,async,wait,mapConcurrently_)
countdowntest :: Maybe Int -> Maybe Int -> IO ()
countdowntest mn mt = do
-- mn: N
-- mt: Zahl der Threads
case (mn,mt) of
(Just n,Just t) -> do
tstore <- C.resetCounter (C.M (C.MAX n))
let nList = [1..t]
mapConcurrently_ (\i -> C.decCounter tstore (C.Steps 0) i) nList
c <- Lib.getTVar tstore
putStrLn $ "Countdown from " ++ (show n) ++ " using " ++ (show t) ++ " cores stopped at: " ++ (show c)
_ -> putStrLn "The countdown command takes exactly two numbers."
Die Liste nList besteht aus der Ziffernfolge 1 bis t, die der Funktion mapConcurrently_ des Moduls Control.Concurrent.Async übergeben wird, um so viele Threads gleichzeitig zu initialisieren, wie nList an Elementen besitzt.
(Bild: Anzela Minosi)
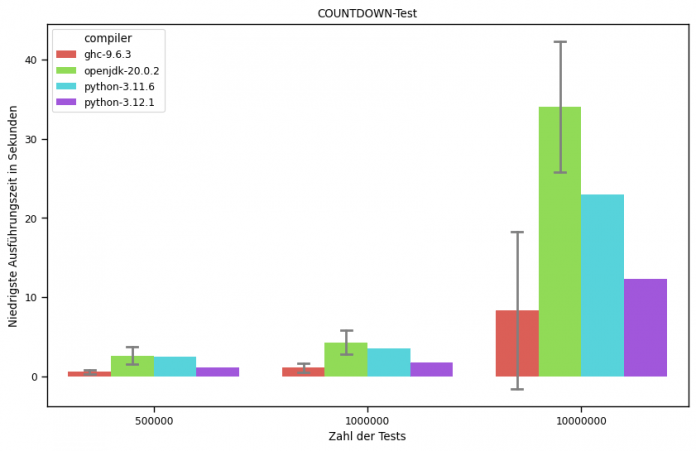
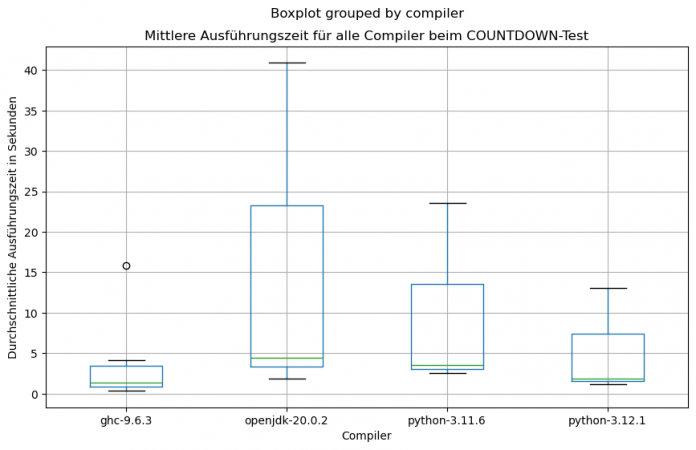
In unserer Testumgebung schnitt Haskell auf beiden Testrechnern am schnellsten ab (siehe Tabelle 3), was nicht zuletzt die gemessenen Durchschnittswerte belegen (Abbildung 5).
(Bild: Anzela Minosi)
Dass Python in diesem Test besser als Java rangiert, hat maßgeblich damit zu tun, dass die Implementierung von thread-sicheren Variablen einen gewissen Overhead mit sich bringt. Würden bei unserer Umsetzung der Countdown-Funktion unter Python mehrere Clients gleichzeitig zugreifen, würde die Ausführung instabil. Der Boxplot in Abbildung 6 zeigt überdies, dass die Tests unter Haskell über eine minimale Range verfügen, zu sehen an der Länge der Box. Auch ist die Entfernung zu den absoluten Minima und Maxima (siehe obere und untere horizontale Linien) bei Haskell nicht allzu groß, sodass dies von einer gewissen Zuverlässigkeit des Haskell-Compilers zeugt.
Die grüne Linie zeigt den absoluten Durchschnittswert der Messungen pro Compiler an.
(Bild: Anzela Minosi)
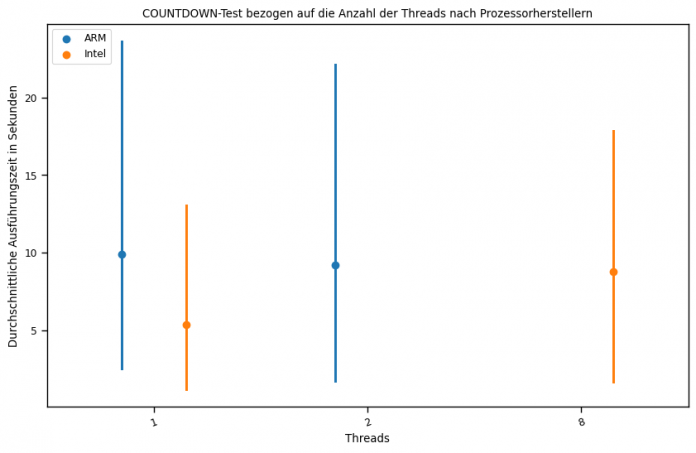
Unterschiede in Bezug auf die Messwerte ergeben sich darüber hinaus beim Vergleich zwischen Intel- und ARM-CPU. So fällt die durchschnittliche Ausführungszeit deutlich geringer aus, wenn mehr Threads zum Einsatz kommen (Abbildung 7).
| Tabelle 3: Testergebnisse: N = 18 | |||||||
| N | Durchschnitt (Sekunden) | Bestwert | Höchstwert | Std-Abweichung | Compiler | Threads | CPU |
| 500000 | 0.34600 | 0.33470 | 0.36990 | 0.01050 | ghc-9.6.3 | 2 | ARM |
| 1000000 | 1.07600 | 0.65400 | 4.74400 | 1.28900 | ghc-9.6.3 | 2 | ARM |
| 10000000 | 4.10800 | 1.32600 | 6.58200 | 2.16600 | ghc-9.6.3 | 2 | ARM |
| 500000 | 0.82900 | 0.76190 | 0.89240 | 0.47800 | ghc-9.6.3 | 8 | Intel |
| 1000000 | 1.60700 | 1.49300 | 1.74200 | 0.08200 | ghc-9.6.3 | 8 | Intel |
| 10000000 | 15.81700 | 15.38200 | 16.33400 | 0.27200 | ghc-9.6.3 | 8 | Intel |
| 500000 | 3.47900 | 3.41200 | 3.51800 | 0.03700 | openjdk-20.0.2 | 2 | ARM |
| 1000000 | 5.43400 | 5.35200 | 5.54600 | 0.06600 | openjdk-20.0.2 | 2 | ARM |
| 10000000 | 40.91400 | 39.87300 | 42.07300 | 0.74700 | openjdk-20.0.2 | 2 | ARM |
| 500000 | 1.90200 | 1.84800 | 1.99100 | 0.03800 | openjdk-20.0.2 | 8 | Intel |
| 1000000 | 3.35700 | 3.26500 | 3.61200 | 0.10500 | openjdk-20.0.2 | 8 | Intel |
| 10000000 | 29.16500 | 28.20000 | 30.87900 | 0.90000 | openjdk-20.0.2 | 8 | Intel |
| 500000 | 2.50500 | 2.45300 | 2.60100 | 0.04300 | python-3.11.6 | 1 | ARM |
| 1000000 | 3.58300 | 3.51500 | 3.64400 | 0.04300 | python-3.11.6 | 1 | ARM |
| 10000000 | 23.62200 | 22.94400 | 23.98700 | 0.31400 | python-3.11.6 | 1 | ARM |
| 500000 | 1.19200 | 1.15800 | 1.26900 | 0.03300 | python-3.12.1 | 1 | Intel |
| 1000000 | 1.87100 | 1.75700 | 2.43300 | 0.20400 | python-3.12.1 | 1 | Intel |
| 10000000 | 13.05300 | 12.30300 | 16.41200 | 1.19000 | python-3.12.1 | 1 | Intel |
Fazit
Der Countdown-Test zeigt, dass der Haskell-Compiler aufgrund der STM-Technologie im Vergleich zu Java und Python unschlagbar ist. Die Implementierung von gemeinsam genutzten Variablen demonstriert, dass Haskell über eine leserliche und prägnante Syntax verfügt, während unter Java mehr Zeilen an Code erforderlich sind. Der Countdown-Test hat überdies gezeigt, dass die parallele Ausführung von Funktionen auch unter Python flott erfolgt, jedoch ist dort der gleichzeitige Zugriff durch mehrere Clients problematisch. Darüber hinaus verhindert der GIL bis zur Version 12, dass Threads gleichzeitig ausgeführt werden. Das aktuelle Release von Python bietet nun eine experimentelle Variante ohne GIL, die Multithreading erleichtert.
Nachtrag
Aufgrund der Diskussion im Forum haben wir die Autorin gebeten, uns die gesamten Haskell-Skripte zur Verfügung zu stellen. Sie betont, dass sämtliche Tests Konsolen-Ausgaben enthielten: "Wenn der Code keine Ausgaben enthielte, dann wären auch bei mir die Tests in 0.NIX durchgelaufen". Wie das folgende Bild verdeutlicht.
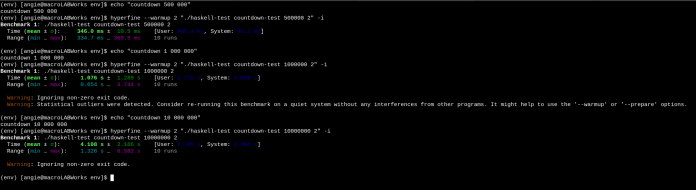
(Bild: Anzela Minosi)
Im Folgenden nun die Skripte:
module MyCounter
(
countdown
, resetCounter
, decCounter
, decT
, loopCounter
, inc
, MAX(..)
, MIN(..)
, MyCounter(..)
, Countdown(..)
, Steps (..)
) where
import Control.Monad (forever)
import Control.Concurrent.STM
import Control.Concurrent.MVar
import Control.Concurrent (forkIO,threadDelay)
import System.Exit as Exit
import qualified Lib as Lib
data MyCounter = MyCounter Int deriving (Eq)
data Countdown = C MyCounter | M MAX | N MIN deriving (Show,Eq)
data MAX = MAX Int deriving (Eq)
data MIN = MIN Int deriving (Eq)
data Steps = Steps Int deriving (Eq)
type CounterVar = TVar Countdown
instance Show MyCounter where
show (MyCounter i) = show i
instance Show MAX where
show (MAX i) = show i
instance Show MIN where
show (MIN i) = show i
instance Show Steps where
show (Steps i) = "Modified counter " ++ (show i) ++ " times."
myCompare :: Countdown -> Countdown -> Ordering
(M (MAX n)) `myCompare` (C (MyCounter i))
| n == i = EQ
| n < i = LT
| otherwise = GT
(N (MIN n)) `myCompare` (C (MyCounter i))
| n == i = EQ
| n < i = LT
| otherwise = GT
c@(C (MyCounter _)) `myCompare` m@(N (MIN _)) = m `myCompare` c
c@(C (MyCounter _)) `myCompare` m@(M (MAX _)) = m `myCompare` c
resetCounter :: Countdown -> IO CounterVar
resetCounter (M (MAX n)) = do
tstore <- atomically $ newTVar (C (MyCounter n))
return tstore
resetCounter (N (MIN n)) = do
tstore <- atomically $ newTVar (C (MyCounter n))
return tstore
decCounter' :: Countdown -> Countdown
decCounter' (C (MyCounter c)) = C (MyCounter (c - 1))
incCounter' :: Countdown -> Countdown
incCounter' (C (MyCounter c)) = C (MyCounter (c + 1))
inc :: CounterVar -> IO ()
inc tstore = do
v <- Lib.getTVar tstore
let newValue = incCounter' v
Lib.modifyTVar_ tstore newValue
decT :: CounterVar -> IO ()
decT r = do
v <- Lib.getTVar r
let min' = N (MIN 0)
newCounter = decCounter' v
putStrLn $ show newCounter
atomically $ (
do
check (myCompare min' v == LT )
writeTVar r newCounter
--decT r
)
decCounter :: CounterVar -> Steps -> Int -> IO ()
decCounter tstore s@(Steps n) i = do
c <- Lib.getTVar tstore
let min' = N (MIN 0)
newCounter = decCounter' c
res = auxCompare min' c
if (auxCompare min' c == LT )
then do
Lib.modifyTVar_ tstore newCounter
decCounter tstore (Steps (succ n)) i
else (putStrLn $ "Finished Thread Number: " ++ (show i)) >> return ()
where
auxCompare x y = x `myCompare` y
countdown :: CounterVar -> Int -> IO ()
countdown tstore 0 = return ()
countdown tstore n = do
forkIO $ decCounter tstore (Steps 0) n
countdown tstore (n-1)
loopCounter :: CounterVar -> Int -> IO ()
loopCounter _ 0 = return ()
loopCounter tstore n = do
c <- Lib.getTVar tstore
putStrLn $ "Current value: " ++ (show c)
loopCounter tstore (n-1)
module MyCLI
(
dispatch
) where
import qualified MyCounter as C
import qualified Lib as Lib
import qualified Data.Text as T
import Control.Concurrent.Async (replicateConcurrently_,async,wait,mapConcurrently_)
import Text.Read (readMaybe)
import GHC.Conc (numCapabilities)
import Control.Monad (forever)
import Control.Concurrent (forkIO,threadDelay)
import System.Random (mkStdGen,getStdGen,StdGen)
import Data.List (take)
lastBits :: Int
lastBits = 10
threshold :: Int
threshold = 100000
localHost :: Server.MyHost
localHost = Server.MyHost "127.0.0.1"
maxConns :: C.MAX
maxConns = C.MAX 4096
dispatch :: String -> [String] -> IO ()
dispatch "countdown-test" args = countdownTest args
dispatch command args = doesntExist command args
doesntExist :: String -> [String] -> IO ()
doesntExist command _ =
putStrLn $ "The " ++ command ++ " command doesn't exist."
countdownTest :: [String] -> IO ()
countdownTest (nString:[]) = do
let mn = readMaybe nString :: Maybe Int
auxCountdowntest mn Nothing
countdownTest (nString:numString:[]) = do
let mn = readMaybe nString :: Maybe Int
mt = readMaybe numString :: Maybe Int
auxCountdowntest mn mt
countdownTest _ = putStrLn "The countdown command takes exactly two arguments."
auxCountdowntest :: Maybe Int -> Maybe Int -> IO ()
auxCountdowntest mn mt = do
case (mn,mt) of
(Just n,Just t) -> do
tstore <- C.resetCounter (C.M (C.MAX n))
r <- async $ C.loopCounter tstore n
let nList = [1..t]
mapConcurrently_ (\i -> C.decCounter tstore (C.Steps 0) i) nList
c <- Lib.getTVar tstore
putStrLn $ "Countdown from " ++ (show n) ++ " using " ++ (show t) ++ " cores stopped at: " ++ (show c)
(Just n,_) -> do
tstore <- C.resetCounter (C.M (C.MAX n))
r <- async $ C.loopCounter tstore n
let nList = [1..numCapabilities]
mapConcurrently_ (\i -> C.decCounter tstore (C.Steps 0) i) nList
c <- Lib.getTVar tstore
putStrLn $ "Countdown from " ++ (show n) ++ " using " ++ (show numCapabilities) ++ " cores stopped at: " ++ (show c)
_ -> putStrLn "The countdown command takes exactly two numbers."
module Main (main) where
import System.Environment (getArgs)
main :: IO ()
main = do
(command:argList) <- getArgs
CLI.dispatch command argList
module Lib
(
modifyTVar_
, getTVar
, async
, printList
, finiteRandoms
, toString
) where
import Control.Monad (forever)
import Control.Concurrent.STM
import Control.Concurrent (forkIO)
import System.IO.Unsafe (unsafePerformIO)
import System.Random
import Data.List (intercalate)
import qualified Data.Text as T
data Async a = Async (TVar a)
--async :: IO a b -> TVar a -> b -> Int -> IO String
--async :: (IO a b) -> a -> b -> [Char] -> IO [Char]
async :: (Show c,Show b) => (a -> b -> IO ()) -> a -> b -> c -> IO ()
async action tstore x n = do
tId <- forkIO ( do
r <- action tstore x
putStrLn $ "Finished Thread Number: " ++ (show n) ++ " :: "++(show r)
)
return ()
modifyTVar_ :: TVar a -> a -> IO ()
modifyTVar_ tv newVal = do
atomically $ writeTVar tv newVal
-- gets the variable stored in a tv variable
getTVar :: TVar b -> IO b
getTVar tv = do
store <- atomically $ readTVar tv
return store
getTvalue :: TVar (Maybe T.Text) -> String
getTvalue tstore = case (unsafePerformIO $ getTVar tstore) of
Just mytext -> T.unpack mytext
_ -> ""
printList :: (Show a) => [a] -> IO ()
printList xs = mapM_ print xs
toString :: (Show a) => [a] -> String
toString xs = intercalate ", " (map show xs)
finiteRandoms :: (RandomGen g, Random a, Num n, Eq n) => n -> g -> ([a],g)
finiteRandoms 0 gen = ([],gen)
finiteRandoms n gen =
let (value,newGen) = random gen
(restOfList, finalGen) = finiteRandoms (n-1) newGen
in (value:restOfList,finalGen)
Aufgrund der Hinweise im Forum haben wir einen Nachtrag mit den kompletten Haskell-Skripten und einem Bild der Konsole-Ausgaben angefügt. Ferner gab es noch eine kleine Korrektur in der prepare-Methode im Java-Code.
(who [11])
URL dieses Artikels:
https://www.heise.de/-9675147
Links in diesem Artikel:
[1] https://www.tiobe.com/tiobe-index/
[2] https://peps.python.org/pep-0703
[3] https://www.heise.de/news/Python-Plaene-fuer-effizienteres-Multithreading-ohne-Global-Interpreter-Lock-9232435.html
[4] https://www.heise.de/news/Python-3-13-Endlich-effizienteres-Multithreading-ohne-Global-Interpreter-Lock-9655663.html
[5] https://www.heise.de/ratgeber/Effizientes-Multithreading-mit-Python-GIL-Probleme-beim-Programmieren-umgehen-7367559.html
[6] https://bell-sw.com/pages/downloads/
[7] https://picocli.info/
[8] https://docs.haskellstack.org/en/stable/
[9] https://github.com/sharkdp/hyperfine
[10] https://trio-parallel.readthedocs.io/en/latest/
[11] mailto:who@heise.de
Copyright © 2024 Heise Medien