Nanoservices – kleiner als Microservices
Microservices lassen sich unabhängig skalieren, und der Ausfall eines Service beeinflusst die anderen nicht. Je kleiner er ist, desto größer der Vorteil – aber wo liegt die Grenze für die Größe eines Microservice? Für noch kleinere Nanoservices sind einige Kompromisse notwendig.

Microservices [1] lassen sich von getrennten Teams ohne größeren Kommunikations-Overhead entwickeln. Das ermöglicht große Projekte mit einer schlanken Organisation. Es gibt zudem technische Vorteile: Microservices lassen sich unabhängig skalieren, und der Ausfall eines Service beeinflusst die anderen nicht. Je kleiner er ist, desto größer der Vorteil – aber wo liegt die Grenze für die Größe eines Microservice? Für noch kleinere Nanoservices sind einige Kompromisse notwendig.
In der Vergangenheit war die Modularisierung eines Softwaresystems meistens nur für Entwickler relevant – schließlich sollten sie die Module getrennt weiterentwickeln. Später wird die gesamte Anwendung auf einmal in den Betrieb überführt: Sie ist also ein Deployment-Monolith. Microservices teilen Anwendungen auch beim Deployment in kleine Einheiten auf. Das Besondere ist, dass sie sich einzeln in Produktion bringen lassen.
Ein Beispiel: Eine E-Commerce-Anwendung hat jeweils Module für den Bestellprozess, für die Produktsuche oder für Empfehlungen. Sind diese Fachlichkeiten als Microservices implementiert, können neue Versionen einzeln in Produktion gebracht werden. Jede dieser Fachlichkeiten lässt sich außerdem in mehrere Microservices aufteilen.
Microservices sind in virtuelle Maschinen oder Docker-Container verpackt: So können sie Bestandteile wie eine eigene Datenbank oder einen Webserver mitbringen und dennoch einzeln deployt werden. Dadurch lassen sich Microservices praktisch in jeder Programmiersprache und auf jeder Plattform implementieren. Im Beispiel kann also jeder Microservice einen Teil der Oberfläche für die Kunden beisteuern.
Microservices haben einige Vorteile, etwa die Entkopplung der Entwicklung durch unabhängige Deployments. Beispielsweise kann ein Team den Bestellprozess eigenständig weiterentwickeln, ohne dass dazu viel Interaktion mit anderen Teams notwendig ist. Schließlich lassen sich für jeden Microservice unterschiedliche Technologien nutzen, sodass ihre Koordination im gesamten Projekt nicht unbedingt notwendig ist. Außerdem kann das Team Änderungen am Microservice ausrollen, ohne das mit den anderen Teams zu koordinieren.
Diese Eigenschaften ermöglichen es, dass auch in einem großen System kleine Teams ohne großen Overhead viele neue Features parallel entwickeln und in Produktion bringen. Aber es gibt noch ganz andere Gründe für Microservices. Beispielsweise sind sie gegeneinander isoliert. Wenn ein Service abstürzt, beeinflusst das die anderen nicht. Ganz anders beim Deployment-Monolithen: Hat ein Modul ein Speicherleck, reißt es beim Absturz das gesamte System mit sich und damit auch alle anderen Module.
Die Größe eines Microservice
Für Microservices gilt eigentlich, dass kleiner besser ist:
- Ein Microservice sollte von nur einem Team weiterentwickelt werden. Daher darf ein solcher Service auf keinen Fall so groß sein, dass mehrere Teams an ihm entwickeln müssen.
- Microservices sind ein Modularisierungsansatz. Entwickler sollten einzelne Module verstehen können – daher müssen Module und damit Microservices so klein sein, dass alle Entwickler sie noch verstehen.
- Schließlich soll ein Microservice ersetzbar sein. Ist er nicht mehr wartbar oder soll beispielsweise eine leistungsfähigere Technologie genutzt werden, lässt er sich durch eine neue Implementierung austauschen. Microservices sind damit der einzige Ansatz, der bereits bei der Entwicklung die Ablösung des Systems oder zumindest von Teilen davon betrachtet.

Die Frage ist nun, warum man die Microservices nicht möglichst klein baut. Dafür gibt es mehrere Gründe:
- Verteilte Kommunikation zwischen Microservices über das Netz ist mit großem Aufwand verbunden. Sind sie größer, ist die Kommunikation eher lokal in einem Microservice und damit weniger aufwendig.
- Jeder Microservice muss unabhängig in Produktion gebracht werden und daher eine eigene Umgebung haben. Das verbraucht Hardwareressourcen und bedeutet, dass der Aufwand für die Administration des Systems steigt. Wenn es größere und damit weniger Microservices gibt, sinkt dieser.
Die ideale Größe eines Microservice ist also nicht fest, sondern hängt von den genutzten Technologien ab. Wenn sie nicht sehr effizient sind, wird er entsprechend groß sein müssen, damit sich der Aufwand für das Bereitstellen der Umgebungen noch rechtfertigen lässt.
Nanoservices Java EE, OSGi, Lambda
Nicht mehr "micro", sondern "nano"
Die Frage ist nun, ob eine geeignete technische Basis die mögliche Größe eines Microservice reduzieren kann. Ein häufiges Fundament für Microservices sind Docker-Container. Sie nutzen Linux-Container zur Isolation der Services und bieten ein effizientes Dateisystem, bei dem sich mehrere Services gemeinsame Snapshots des Systems teilen können. Aber es ist für jeden Microservice immer noch ein eigenes Dateisystem zu erstellen, und jeder hat einen eigenen Betriebssystemprozess. Für einige wenige Zeilen Code kann das nicht mehr vertretbar sein.
Um die Größe eines Microservice zu reduzieren, sind Kompromisse denkbar. Zentrale Eigenschaft eines Microservice ist das unabhängige Deployment. Kompromisse in diesem Bereich sind also kaum sinnvoll, aber bei der Isolation der Microservices gegeneinander oder der freien Wahl der Technologien durchaus denkbar. Um diese Idee klar von klassischen Microservices zu unterscheiden, nutzt der Autor den Begriff Nanoservice: Die Services sind kleiner als klassische Microservices, aber sie gehen auch einige Kompromisse ein, sodass sie keine echten Microservices mehr sind.
Nanoservices im Kontext von Java EE
Die Java Enterprise Edition (Java EE) ist ein Standard aus dem Java-Bereich. Er definiert APIs aus unterschiedlichen Bereichen wie Servlets, JSF (JavaServer Faces) und JSP (JavaServer Pages) für Webanwendungen sowie JTA (Java Transaction API) für Transaktionen und JPA (Java Persistence API) für Persistenz. Bei der Implementierung der APIs spielen auch Features wie die Verwaltung von Netzwerkverbindungen oder Threads eine Rolle. Außerdem standardisiert Java EE ein Deployment-Modell. Webanwendungen lassen sich in ein WAR (Web Archive) verpacken. JARs (Java Archives) können Logik in EJBs (Enterprise JavaBeans) und Bibliotheken enthalten. In einem EAR (Enterprise Archive) können JARs und WARs zu einer Anwendung verpackt werden.
Ursprünglich war die Idee der Application Server, dass sich mehrere Java-Anwendungen die Infrastruktur eines Servers teilen. Mittlerweile benötigen viele Anwendungen aber einen Cluster von Anwendungsservern, sodass ein Deployment mehrere Applikationen in einem einzigen Server kaum noch zeitgemäß ist.
In Java EE bedeutet Anwendung ein WAR, JAR oder EAR. Der Code aus der einen ist für die anderen Anwendungen nicht sichtbar. Allerdings reicht die Isolation nicht besonders weit: Wenn eine Applikation die CPU stark belastet oder viel Speicher verbraucht, beeinflusst das die anderen Anwendungen. Auch beim unabhängigen Deployment ergeben sich Herausforderungen: In der Praxis werden Application Server nach dem Deployment einer neuen Anwendungsversion neu gestartet, um zu garantieren, dass die alte Version vollständig aus dem Speicher entfernt worden ist.
Da der Code der Anwendungen vollständig voneinander getrennt ist, können sie keinen gemeinsamen Code haben und auch nicht direkt über Methodenaufrufe kommunizieren. Also müssen die Nanoservices genauso wie ihre größeren Vorbilder über das Netzwerk und damit über HTTP, REST oder Messaging kommunizieren.
Ebenso ist die Technologiewahl eingeschränkt: Es lassen sich nur Programmiersprachen nutzen, die auf der JVM (Java Virtual Machine) zur Verfügung stehen. Aber nicht nur die Wahl der Programmiersprache ist begrenzt – selbst die der Plattform. Java-Anwendungsserver nutzen ein synchrones Modell für das Behandeln von Anfragen. Für jede Anfrage verwendet der Application Server einen Thread, der auch für den Aufruf anderer Systeme genutzt wird und durch das Warten auf diese Daten blockiert ist.
Es gibt auf der JVM alternative Modelle wie Vert.x [2] oder das Play Framework [3], die asynchron arbeiten. Sie haben einen Event-Loop, bei dem ein Thread Ereignisse abarbeitet. Ein Aufruf an ein anderes System blockiert also keinen Thread, sondern sorgt nur dafür, dass ein neuer Event eingestellt wird, wenn die Daten des anderen Systems verfügbar sind. Weil der Application Server aber die Behandlung von Threads und Netzwerkverbindungen übernimmt, ist ein solcher Ansatz in einem Java-EE-Umfeld nicht ohne weiteres umsetzbar. Integrationen asynchroner Techniken in Java EE gibt es zwar, aber weite Teile des Ansatzes sind dennoch synchron.
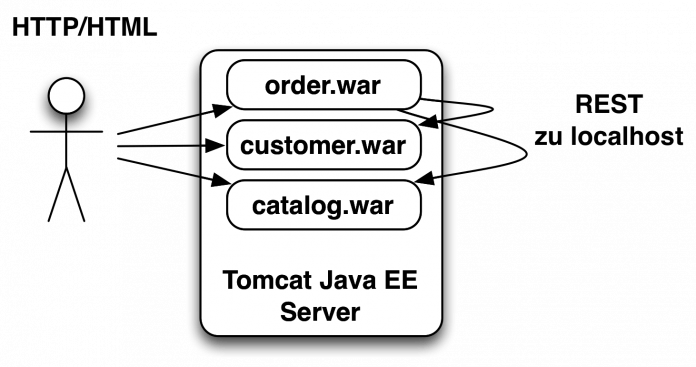
Letztlich würde also ein Nanoservice so aussehen, wie Abbildung 3 es zeigt: Jeder Service ist eine WAR-Datei. Die Services nutzen untereinander REST und können jeweils für den Nutzer HTML über HTTP zur Verfügung stellen. Ein passendes Beispiel [4] gibt es ebenfalls. Die Umsetzung hat jedoch ihre Nachteile: Wenn der Application Server ausfällt, sind gleich alle Services ausgefallen. Bei einem Microservice-Ansatz ließe sich das verhindern, weil man die Services auf unterschiedlichen virtuellen Servern installiert. Natürlich kann es mehrere Instanzen des Application Server geben – aber wenn jeder Server ein WAR mit einem Speicherleck hat, nützt das nur wenig. Weil ein Application Server verschiedene Services beheimatet, lassen sie sich auch nicht mehr
unabhängig voneinander skalieren.
Nanoservices mit OSGi
Bei OSGi [5] handelt es sich ebenfalls um einen Standard. Es ist ein Modularisierungsansatz für die JVM. Die Module heißen Bundles und basieren auf JAR-Dateien, die Java EE ebenfalls nutzt. Allerdings können bei OSGi die JARs Code exportieren und importieren. Im Gegensatz zu Java EE kann es also gemeinsam genutzten Code geben. Allerdings werden dadurch auch Änderungen an den Bundles schwieriger: Wenn ein Bundle Code exportiert und ein anderes ihn importiert, ist bei einer Änderung des exportierenden Bundles auch das importierende neu zu starten. Das bedeutet aber, dass ein Deployment eines Bundles zusätzlich andere Bundles beeinflusst. Daher lassen sie sich scheinbar nicht so ohne weiteres zur Umsetzung von Micro- oder Nanoservices nutzen.
Bundles können Services exportieren. Das sind letztlich Java-Objekte, die von anderen Bundles aus aufgerufen werden können. Um die Implementierung eines Services zur Laufzeit ändern zu können, hat sich in der OSGi-Welt ein Pattern etabliert:
- Das Schnittstellen-Bundle enthält den Code für die Schnittstelle des Services. Jedes Bundle, dass den Services nutzen will, importiert die Schnittstelle.
- Das Service-Bundle enthält die Implementierung des Service. Es exportiert ihn, aber keinen Code. Die Schnittstelle importiert es aus dem Schnittstellen-Bundle.
- Ein Client-Bundle importiert den Service aus dem Service-Bundle und die Schnittstelle aus dem Schnittstellen-Bundle.
Wenn nun eine Änderung am Service notwendig ist, ist nur das Service-Bundle neu auszuliefern. Dann steht zwar der Service für einige Zeit nicht zur Verfügung, aber das Client-Bundle ist nicht neu zu starten. Nur wenn Änderungen an der Schnittstelle notwendig sind, muss man alle drei Bundles neu installieren und starten. OSGi-Services erzwingen also keine Deployment-Abhängigkeiten und können als Umsetzung von Nanoservices dienen.
Allerdings gilt auch für OSGi wie schon für Java EE, dass sich Bundles zwar theoretisch einzeln neu starten lassen, aber in der Praxis oft das gesamte System einen Neustart erfordert. Die Entwicklungsumgebung Eclipse ist ein solches Beispiel: Sie ist zwar in OSGi Bundles aufgeteilt, aber bei einem Update werden dann nicht nur die einzelnen Bundles neu gestartet, sondern der gesamte Prozess. Also ist das unabhängige Deployment einzelner Bundles oft so nicht realistisch nutzbar.
Ansätze wie OSGi Blueprints [6] oder OSGi Declarative Services [7] vereinfachen die Implementierung von OSGi-Services und können einen vorübergehenden Ausfall eines Services kompensieren. Auf jeden Fall unterstützen OSGi-Services lokale Kommunikation – also Methodenaufrufe in der JVM ohne Kommunikation über das Netzwerk. Das ist effizienter als die verteilte Kommunikation von Microservices.
Auch bei OSGi ist die Nutzung der Technologien eingeschränkt: Es lassen sich nur JVM-Technologien verwenden. OSGi greift zwar nicht wie ein Application Server in die Handhabung von Threads und Netzwerkverbindungen ein, aber das Laden von Klassen funktioniert anders als in einfachen Java-Systemen, um Bundles und den Im- und Export von Klassen zu unterstützen. Das erzwingt eine Unterstützung in den Bibliotheken.
Nanoservices mit Amazon Lambda
Amazon Lambda [8] ist ein Dienst in Amazons Cloud-Umgebung. Er ist in sämtlichen Rechenzentren des Cloud-Betreibers verfügbar. Mit ihm lassen sich einzelne Funktionen installieren und ausführen. Lambda unterstützt für die Implementierung der Funktionen Java, JavaScript mit Node.js und Python. Jede Funktion lässt sich einzeln deployen, und jede Ausführung einer Funktion wird einzeln abgerechnet. Der Aufwand für die Infrastruktur ist also minimal: Es ist lediglich ein Skript zum Deployment aufzurufen. Die Metriken und Logs der Funktionen lassen sich mit dem Dienst Cloud Watch überwachen. Auch die Definition von Alarmen ist möglich, wenn bestimmte Werte kritisch werden. Die Funktionen können Anwender auf verschiedene Weisen starten:
- Die Funktion lässt sich direkt per Kommandozeile aufrufen.
- In S3 (Simple Storage Service) kann man große Dateien ablegen und herunterladen. Solche Aktionen lösen Ereignisse aus, auf die eine Amazon-Lambda-Funktion reagieren kann.
- Mit Amazon Kinesis lassen sich Datenströme verwalten und verteilen. Diese Technologie ist auf die Echtzeitverarbeitung großer Datenmengen ausgelegt. Lambda-Funktionen können als Reaktion auf neue Daten in diesen Strömen aufgerufen werden.
- DynamoDB ist eine NoSQL-Datenbank in Amazons Cloud. Sie kann bei Änderungen am Datenbestand der Datenbank Lambda-Funktionen aufrufen, sodass diese praktisch zu Datenbank-Triggern werden.
- Der Simple Notification Service (SNS) wird oft genutzt, um einen Alarm aus dem Monitoring per E-Mail oder SMS weiterzuschicken. Auch SNS kann Lambda-Funktionen aufrufen.
- Amazons Simple Email Service (SES) kann E-Mails verschicken und empfangen. Als Reaktion auf eine E-Mail lässt sich eine Lambda-Funktion aufrufen.
- Mobile Daten wie Spielstände kann Amazon Cognito verwalten. Auch hier ist ein Aufruf einer Lambda-Funktion als Reaktion auf eine Änderung von Daten denkbar.
- Amazon CloudWatch Logs kann Lambda-Funktionen nutzen, um die Logs von Anwendungen zu analysieren.
- Schließlich lassen sich Lambda-Funktionen als Teil von CloudFormation-Skripten nutzen, die eine Umgebung in der Amazon-Cloud aufbauen.
Allerdings ist es nicht ohne weiteres möglich, eine Lambda-Funktion als Reaktion auf einen REST-Zugriff zu aktivieren. Eine Erweiterung mit anderen Technologien ist aber denkbar: Beispielsweise lassen sich mit EC2 virtuelle Rechner nutzen oder mit Elastic Beanstalk Anwendungen in Sprachen wie Java oder Python betreiben. Also können Bereiche, die Lambda nicht abdeckt, in anderen Technologien umgesetzt werden. Die Isolation der einzelnen Lambda-Funktionen ist gut, denn schließlich muss die Infrastruktur auch die Amazon-Kunden gegeneinander isolieren.
Für den Einstieg gibt es ein Tutorial. [9]
Fazit
Ausblick
Neben den hier näher erläuterten Technologien gibt es einige andere Ansätze:
- Vert.x setzt auf eine asynchrone Verarbeitung auf der JVM und unterstützt Sprachen wie Java, JavaScript, Ruby und Groovy. Es bietet also ein gewisses Maß an technischer Freiheit. Vert.x unterstützt ähnlich wie OSGi eine Aufteilung in Module, die sich einzeln deployen lassen und sowohl per lokalen Methodenaufruf kommunizieren oder im Netzwerk verteilt sein können. Sie kommunizieren mit JSON, sodass es keine Code-Abhängigkeiten zwischen den Modulen gibt.
- Erlang [10] nutzt ebenfalls asynchrone Kommunikation zwischen Prozessen. Außerdem bietet die Programmiersprache eine Überwachung der Prozesse, um so beim Ausfall eines Service zu reagieren. Die Services sind auch weitgehend isoliert. Anders als Vert.x unterstützt Erlang zudem Prozesse in anderen Programmiersprachen, die sich ebenfalls überwachen lassen.
Fazit
Möglichst kleine Microservices sind wünschenswert, weil sie so leichter zu verstehen und zu ersetzen sind. Aber in der Praxis begrenzt die Infrastruktur die Größe der Microservices. Die vorgestellten Technologien erlauben zwar kleinere Services, gehen aber bei der Isolation Kompromisse ein: OSGi und Java EE verringern den Ressourcenverbrauch und die Komplexität, wenn mehrere Services in einer JVM laufen. Dann sind sie aber nicht mehr gegeneinander isoliert: Wenn ein Service viel Speicher benötigt oder die CPU stark belastet, werden die anderen entsprechend beeinflusst. OSGi erlaubt die Kommunikation der Services in der JVM, während bei Java EE die Kommunikation durch den Netzwerk-Stack gehen muss. Ebenso erlauben beide nicht mehr ohne weiteres eine einfache Lastverteilung zwischen den Services.
Amazon Lambda ist sehr interessant: Einzelne Methoden lassen sich ohne großen Aufwand deployen. Jeder Aufruf wird abgerechnet, das Monitoring ist ebenfalls problemlos, und die Services sind strikt gegeneinander isoliert – schließlich muss die Plattform sicherstellen, dass Dienste verschiedener Kunden sich nicht aus Versehen beeinflussen. So erlaubt Amazon Lambda ganz andere Ansätze bei der Softwareentwicklung.
Aber es müssen nicht gleich Nanoservices sein: Eine Vereinheitlichung und Vereinfachung der Infrastrukturen kann schon dabei helfen, den Aufwand für Services zu reduzieren und so auch kleinere Services realistisch nutzbar zu machen. Beispielsweise können Templates für neue Services und analog Ansätze für Monitoring und Deployment hilfreich sein.
Eberhard Wolff
arbeitet als Fellow bei der innoQ. Er ist seit mehr als 15 Jahren als Architekt und Berater tätig – oft an der Schnittstelle zwischen Business und Technologie. Sein technologischer Schwerpunkt liegt auf modernen Architektur-Ansätzen – Cloud, Continuous Delivery, DevOps, Microservices oder NoSQL spielen oft eine Rolle.
(ane [11])
URL dieses Artikels:
https://www.heise.de/-3038541
Links in diesem Artikel:
[1] http://microservices-buch.de/
[2] http://vertx.io/
[3] https://www.playframework.com/
[4] https://github.com/ewolff/war-demo/
[5] https://www.osgi.org/
[6] http://wiki.osgi.org/wiki/Blueprint
[7] http://wiki.osgi.org/wiki/Declarative_Services
[8] http://aws.amazon.com/lambda
[9] http://aws.amazon.com/de/lambda/getting-started/
[10] http://www.erlang.org/
[11] mailto:ane@heise.de
Copyright © 2015 Heise Medien